
Amazon SageMaker Processing 処理ジョブを作成してデータ変換ワークロードを実行する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは!よしななです。
今回は、Amazon SageMaker Processing(処理ジョブ)を作成して、
データの前処理を実行してみたいと思います。
目次
- 前提
- Amazon SageMaker Processing について
- 実行したい処理
- 全体像
- データ準備
- S3 バケットの作成
- train.csv を input フォルダに格納
- Amazon SageMaker Processing で実行するデータ処理スクリプトを準備
- 入出力データパスの対応
- Amazon SageMaker Processing の実行
- インスタンスの削除
- 最後に
前提
- OS
- Windows 11
- 本記事の実行には AWS アカウントが必要となります。
Amazon SageMaker Processing について
Amazon SageMaker Processing は、AWS の機械学習マネージドサービス Amazon SageMaker の中で、機械学習のデータ前処理、モデル評価などのタスクを実行するためのサービスとなっています。
参考URL:
概念図は以下の通りとなっていて、以下の3つの指定が必要となります。
- Amazon SageMaker Processing で加工する前のデータが格納されたパス
- Amazon SageMaker Processing で加工された後のデータを格納するパス
- 処理内容(python スクリプト、Docker Image など)
S3 バケットに格納されたデータを、コンテナ上で処理し指定された S3 バケットに書き出すという処理になります。
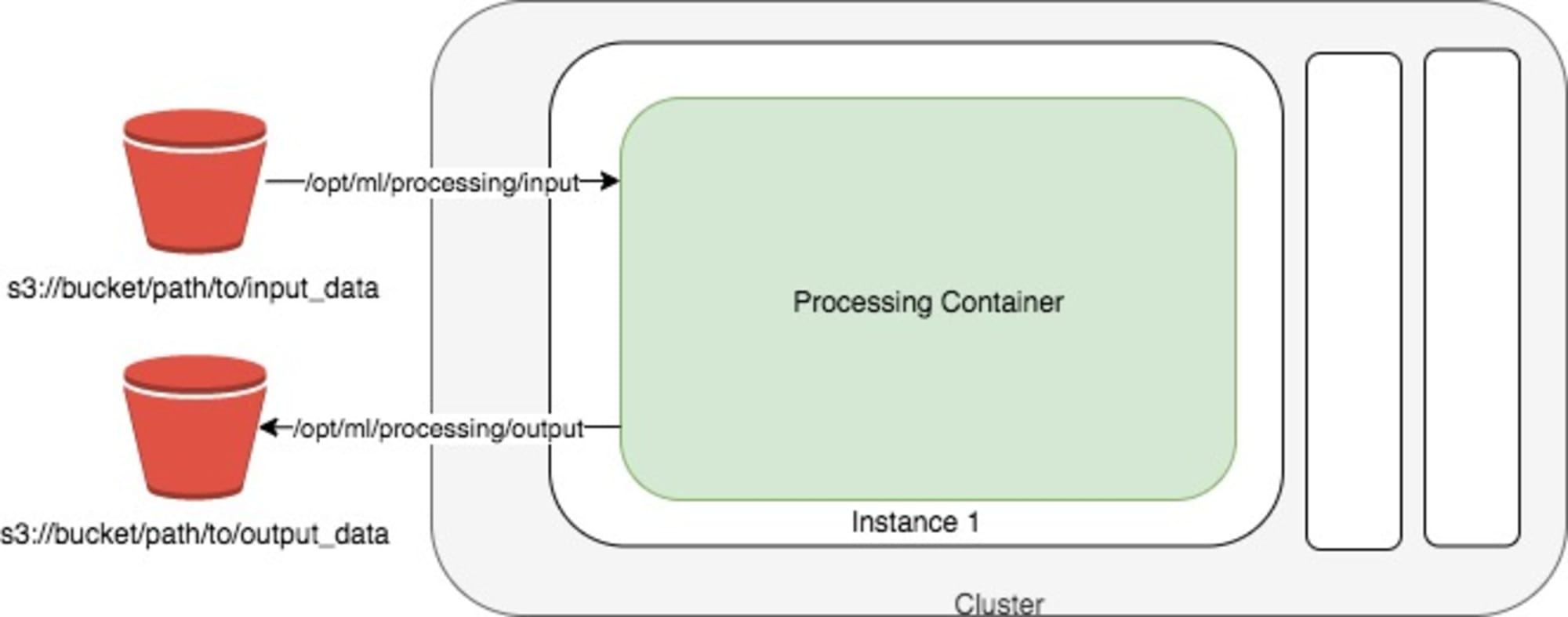
↑Amazon SageMaker Processing 全体像
出典:
Amazon SageMaker Processing では、処理の実行を行うために4つのクラスが用意されています。
それぞれ以下のように使い分けが必要となります。
- Scikit-learn を使用:
SKLearnProcessor - Pyspark を使用:
PySparkProcessor - カスタムコンテナを使用:
ScriptProcessor,Processor
今回は、1. の Scikit-learn を使用するパターンの処理について実行したのでブログにまとめます。
実行したい処理
今回実行したい処理として、こちらの Kaggle データセット:個人の属性と収入に関するデータを用いて、データの加工・train 用と test 用にデータセットを分割の2つの処理を行っていきます。
- 使用するデータセット
- https://www.kaggle.com/datasets/mastmustu/income train.csv を使用する
- データセットに対して行う処理
workclassカラムの欠損値をUnknownで埋めるageが100以上の値を100に制限するgenderのエンコーディングageカラムから年齢層カラムの追加- 教育年数から教育レベルカラムを作成
- 加工したデータを分割
- train.csv を train 用・test 用データに分割を行う
全体像
今回実装する処理の流れとしては以下の図の通りとなります。

データ加工・データ分割の2つの処理をSKLearnProcessorクラスを用いて処理を行っていきます。
SKLearnProcessorクラスの実行は、Amazon SageMaker Notebook 上で行います。
処理に必要な手順は以下の通りとなります。
- 処理に使用する Kaggle データを S3 バケットに保存
- Scikit-learn を使用する処理を実装した .py スクリプトを用意する
- 処理されたデータを格納するための保存先 S3 path を取得
データ準備
S3 バケットの作成
input / output データを格納する S3 バケットを作成します。
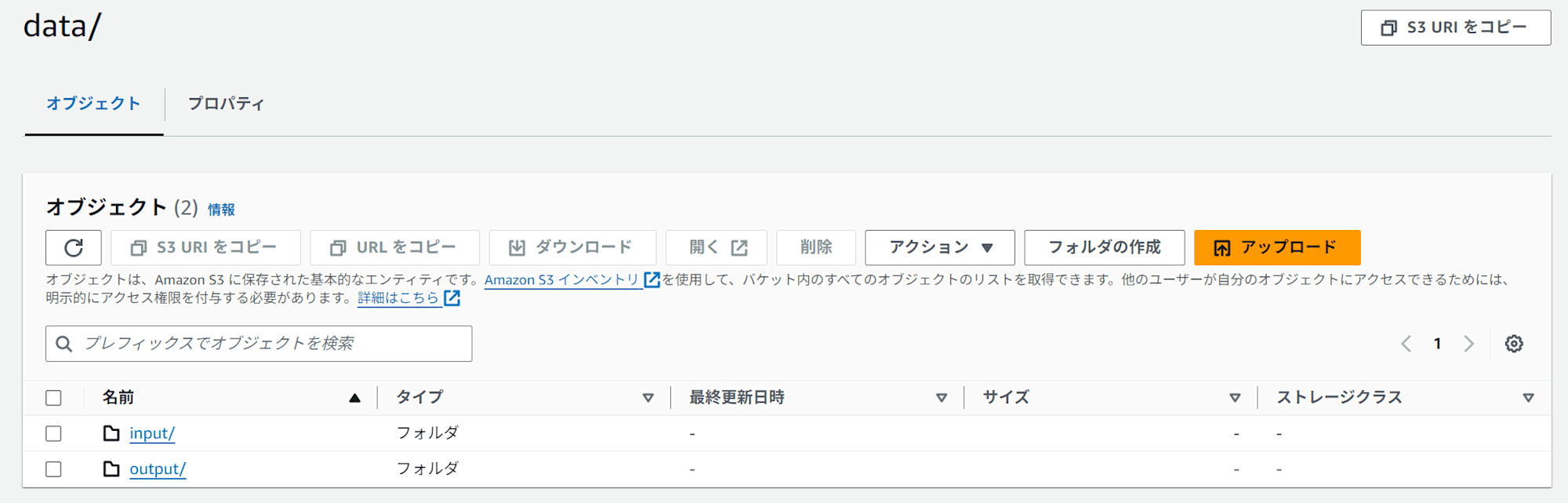
train.csv を input フォルダに格納
https://www.kaggle.com/datasets/mastmustu/income からダウンロードした train.csv をs3://{bucket}/data/inputに保存します。
実際にデータが配置されているかを確認します。
こちらの手順:https://dev.classmethod.jp/articles/sagemaker-easy-python-exec/ を参考に、Amazon SageMaker Notebook を立ち上げます。
Notebook インスタンスが起動したら、Notebook を立ち上げホームディレクトリにsetting.yamlを作成します。
aws:
sagemaker:
s3bucket: "{train.csv が配置されている S3 バケット名}"
その後、立ち上げた Notebook 上で以下を実行します。
# 必要なライブラリのインポート
import pandas as pd
import yaml
import boto3
import sagemaker
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import ProcessingInput, ProcessingOutput
# 設定ファイルのパスを指定
SETTING_FILE_PATH = './settings.yaml'
# YAMLファイルを読み込み、AWS情報を取得
with open(SETTING_FILE_PATH) as file:
aws_info = yaml.safe_load(file)
# SageMakerセッションを初期化
sess = sagemaker.Session()
# S3バケット名を設定ファイルから取得
s3bucket = aws_info['aws']['sagemaker']['s3bucket']
# boto3を使用してS3クライアントを初期化
s3_client = boto3.client('s3',region_name='ap-northeast-1')
# S3バケットから'data/input/train.csv'ファイルをローカルの'train.csv'ファイルにダウンロード
s3_client.download_file(s3bucket, 'data/input/train.csv', './train/train.csv')
# ダウンロードしたCSVファイルをPandasデータフレームとして読み込み
df = pd.read_csv("./train/train.csv")
# データフレームの先頭数行を表示
df.head()
実行結果:
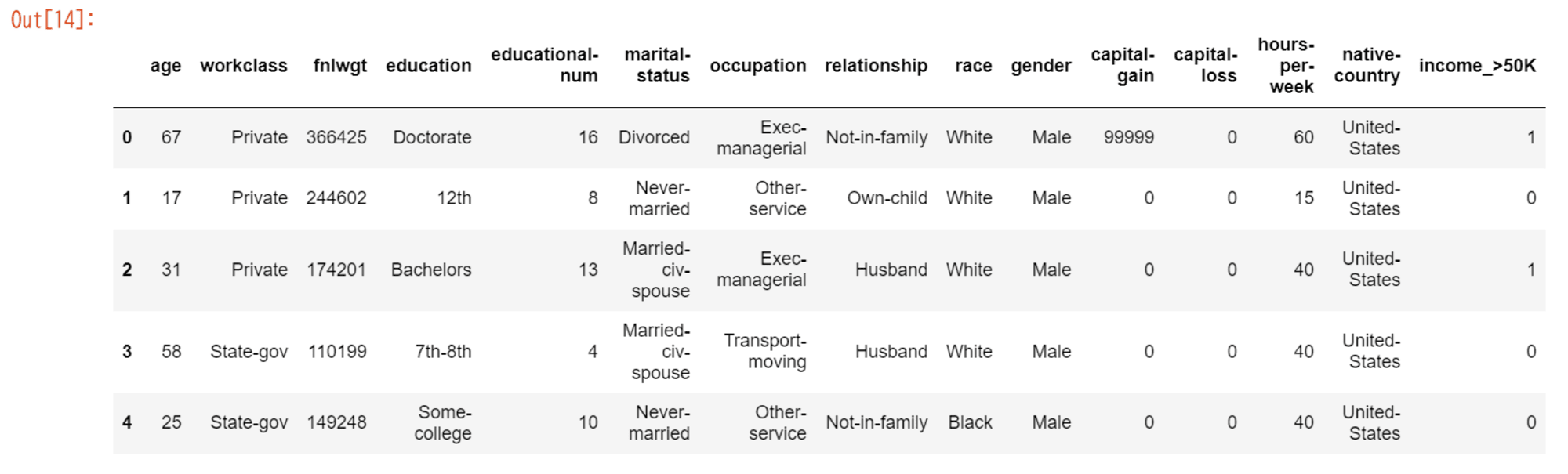
上記の通り、Amazon SageMaker Notebook - S3 バケットの疎通ができました。
S3バケットから'data/input/train.csv'ファイルをローカルの'train.csv'ファイルにダウンロード時に、ClientError: An error occurred (403) when calling the HeadObject operation: Forbiddenのエラーが発生した場合、Notebook インスタンスに付与した IAM ロールの権限が足りない可能性があります。
エラー解消のため、Notebook インスタンスに付与した IAM ロールに対し、以下のカスタマーインラインポリシーを作成し、 IAM ロールに付与しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::{train.csv が配置されている S3 バケット名}",
"arn:aws:s3:::{train.csv が配置されている S3 バケット名}/*"
]
}
]
}
Amazon SageMaker Processing で実行するデータ処理スクリプトを準備
次に、Amazon SageMaker Processing で実行するデータ処理スクリプトを用意します。
実装する内容は主に以下の3つになります。
- 入力データ読み込み
- 任意の処理
- データの処理
workclassカラムの欠損値をUnknownで埋めるageが100以上の値を100に制限するgenderのエンコーディングageカラムから年齢層カラムの追加- 教育年数から教育レベルカラムを作成
- 加工したデータを分割
- train.csv を train 用・test 用データに分割を行う
- データの処理
- 加工データの保存
Amazon SageMaker Processing の特徴として、処理されたデータは Processing 実行時に指定されたパスに保存されます。
今回実装した以下 .py スクリプトでは処理前データのパスをos.path.join("/opt/ml/processing/input","train")と指定し、
処理済データの保存パスを(os.path.join(output_train_data_path, "processed_train_data.csv"), index=False)、(os.path.join(output_test_data_path, "processed_test_data.csv"), index=False)に指定しています。
理由としては、本項で作成するデータ処理スクリプトを Notebook を介して Amazon SageMaker Processing で実行する際に、Notebook 側で S3 のデータをコンテナ内のどのパスに対応させるかを Notebook で指定する必要があるため、処理スクリプト側でデータ操作を行う際は Notebook で指定したパスと統一する必要があります。
※コンテナパスは/opt/ml/processing/で始まる必要があるのでその通りコードを書いていきます。
参考ドキュメント:
実装した preprocessing.py スクリプトは以下となります。
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
def preprocess_data(df):
# 1. 欠損値の処理 'workclass'カラムの欠損値を'Unknown'で埋める
df['workclass'] = df['workclass'].fillna('Unknown')
# 2. 異常値の処理 'age'が100以上の値を100に制限する
df['age'] = df['age'].clip(upper=100)
# 3. カテゴリカル変数のエンコーディング
df = pd.get_dummies(df, columns=['gender'], prefix='gender')
# 4. `age`から年齢層カラムの作成
df['age_group'] = pd.cut(df['age'], bins=[0, 18, 30, 45, 60, 100],
labels=['Under 18', '18-30', '31-45', '46-60', 'Over 60'])
# 5. 教育年数から教育レベルカラムを作成
df['education_level'] = df['educational-num'].apply(education_level)
return df
def education_level(years): # 5. 教育年数から教育レベルカラムを作成
if years <= 8:
return 'Elementary'
elif years <= 12:
return 'High School'
elif years <= 16:
return 'College'
else:
return 'Graduate'
# メイン処理
if __name__ == "__main__":
# データの読み込み
input_train_data_path = os.path.join("/opt/ml/processing/input","train")
df = pd.read_csv(input_train_data_path)
# データの前処理
processed_df = preprocess_data(df)
# データの分割
train_data, test_data = train_test_split(processed_df, test_size=0.2, random_state=42)
# 出力先パス指定
output_train_data_path = "/opt/ml/processing/output/train"
output_test_data_path = "/opt/ml/processing/output/test"
# データの書き出し用フォルダを作成する
try :
os.makedirs(output_train_data_path, exist_ok=True)
os.makedirs(output_test_data_path, exist_ok=True)
except :
pass
# データを直接指定したフォルダに書き出す
try :
train_data.to_csv(os.path.join(output_train_data_path, "processed_train_data.csv"), index=False)
test_data.to_csv(os.path.join(output_test_data_path, "processed_test_data.csv"), index=False)
print("データの書き出しが完了しました。")
except :
pass
作成したスクリプトは、Amazon SageMaker Notebook 上にアップロードします。
入出力データパスの対応
上述した通り、データ処理スクリプトのパスと S3 バケットのパスを対応させます。
SageMaker Processing job の実行時に、以下のクラスを使用することで、データ処理スクリプトのパスと S3 バケットのパスを対応させます。
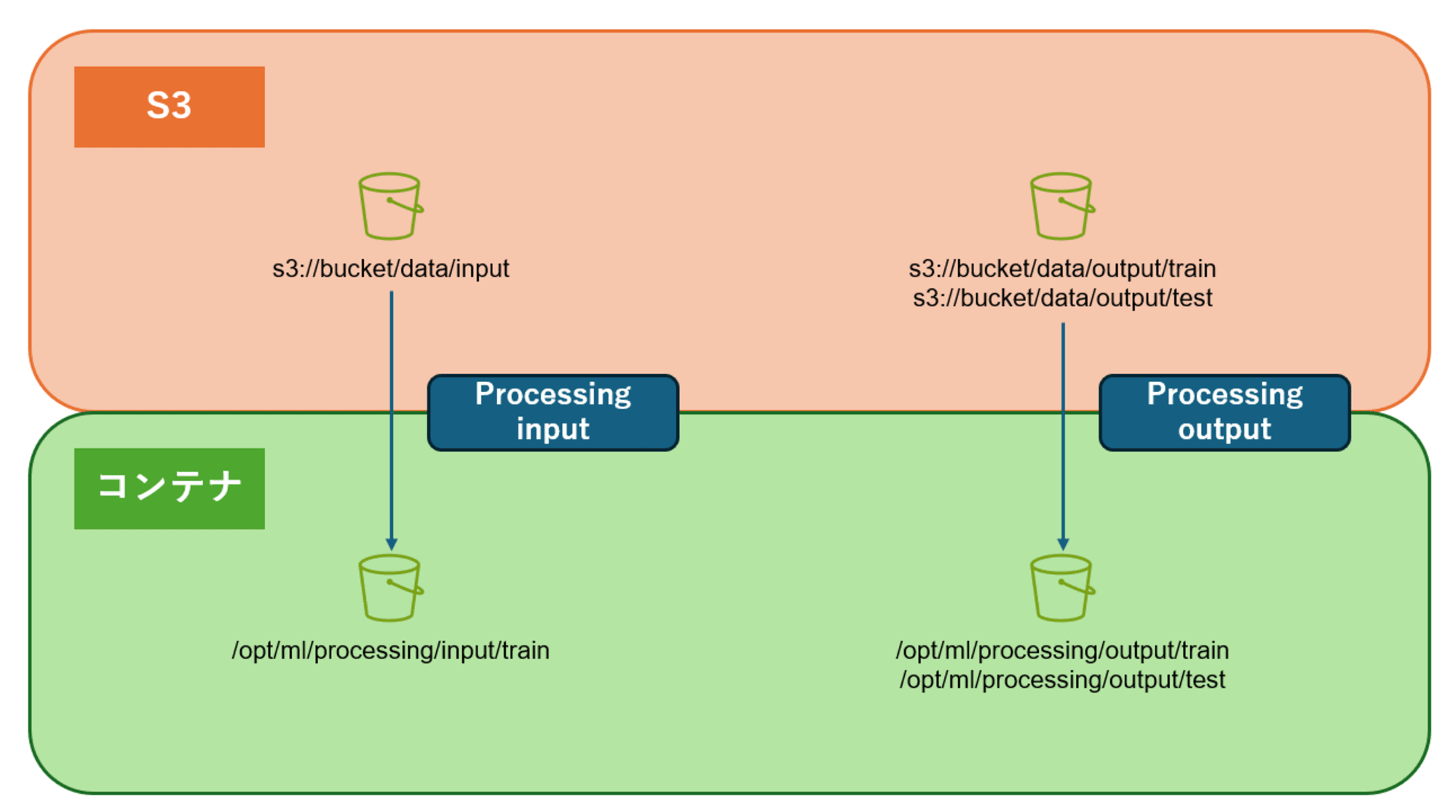
ProcessingInput:入力データsource:入力データが保存されている S3 バケットのパスdestination:Notebook で指定している読み込みデータを保存するコンテナのパス
ProcessingOutput:出力データsource:Notebook で指定している処理済みデータを保存するコンテナのパスdestination:処理済みデータを保存する S3 バケットのパス
イメージ図:
上記を参考にしたコードは以下となります。
次項で、Amazon SageMaker Processing を実行するためのリソース作成などと一緒に以下のコードを Notebook 上で実行していきます。
import sagemaker
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import ProcessingInput, ProcessingOutput
# 設定ファイルのパスを指定
SETTING_FILE_PATH = './settings.yaml'
# YAMLファイルを読み込み、AWS情報を取得
with open(SETTING_FILE_PATH) as file:
aws_info = yaml.safe_load(file)
# 読み込んだ内容から必要な情報を取得
s3bucket = aws_info['aws']['sagemaker']['s3bucket']
# 入力データ、出力データの S3 URI の指定
input_data_s3_uri = "s3://{}/data/input/".format(s3bucket)
output_data_s3_uri = "s3://{}/data/output/".format(s3bucket)
# `ProcessingInput`、`ProcessingOutput`を設定
res = processor.run(
code = "preprocessing.py",
inputs = [ProcessingInput(
source = input_data_s3_uri,
destination = "/opt/ml/processing/input"),
],
outputs = [
ProcessingOutput(
source = "/opt/ml/processing/output/train",
destination = output_data_s3_uri),
ProcessingOutput(
source = "/opt/ml/processing/output/test",
destination = output_data_s3_uri),
],
)
参考ドキュメント:
Amazon SageMaker Processing の実行
それでは、SageMaker Processing を実行していきます。
まず、SageMaker Processing を動かすためのロールが必要になるため、
先ほど作成したsetting.yamlを以下の通り修正します。
aws:
sagemaker:
role: "arn:aws:iam::{自分のAWSアカウントID}:role/service-role/SageMaker-AmazonSageMaker-ExecutionRole"
s3bucket: "{train.csv が配置されている S3 バケット名}"
次に、SKLearnProcessor クラスに使用したい Scikit-learn のバージョン、インスタンスサイズ・台数を指定します。
今回は、テストのため小さいインスタンス:ml.t3.medium、インスタンス台数は1台で実行します。
最後に、以下の引数を指定する必要があります。code、input、outputの値を指定します。
上記、入出力データパスの対応 で記述したコードと一緒に、以下のコードを Notebook 上で実行していきます。
# 必要なライブラリのインポート
import pandas as pd
import yaml
import boto3
import sagemaker
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import ProcessingInput, ProcessingOutput
# 設定ファイルのパスを指定
SETTING_FILE_PATH = './settings.yaml'
# YAML ファイルを読み込み、AWS情報を取得
with open(SETTING_FILE_PATH) as file:
aws_info = yaml.safe_load(file)
# S3 バケット、IAM ロールの情報を設定ファイルから取得
role = aws_info['aws']['sagemaker']['role']
s3bucket = aws_info['aws']['sagemaker']['s3bucket']
# SageMaker セッション初期化
sm = boto3.client('sagemaker')
# インスタンスタイプと台数の指定
processing_instance_type = "ml.t3.medium"
processing_instance_count = 1
# 入力データ、出力データの S3 URI の指定
input_data_s3_uri = "s3://{}/data/input/train.csv".format(s3bucket)
output_data_s3_uri = "s3://{}/data/output/".format(s3bucket)
# SageMaker Processing ジョブ名の指定
processing_job_name = "sklearn-preprocessor-test"
# SageMaker Processing を動かすためのリソースの作成
processor = SKLearnProcessor(
framework_version = "0.23-1",
role=role,
instance_type = processing_instance_type,
instance_count = processing_instance_count,
max_runtime_in_seconds = 7200
)
# SageMaker Processing ジョブの作成
res = processor.run(
code = "preprocessing.py",
inputs = [ProcessingInput(
source = input_data_s3_uri,
destination = "/opt/ml/processing/input/train"),
],
outputs = [
ProcessingOutput(
source = "/opt/ml/processing/output/train",
destination = output_data_s3_uri),
ProcessingOutput(
source = "/opt/ml/processing/output/test",
destination = output_data_s3_uri),
],
wait=True,
logs=False,
job_name=processing_job_name,
experiment_config=None
)
Notebook 実行中画面:
上記 Notebook が実行されると、マネージドコンソールの SageMaker Processing ジョブ一覧に作成したジョブが追加されます。
preprocessing.py の内容が実行完了すると、以下の通りジョブが完了しました。
実行が完了すると、S3に加工データが保存され、インスタンスが自動で終了します。
boto3 のsagemaker client を利用してProcessing Jobの一覧を取得して、実行jobを確認することもできます。
sm = boto3.client('sagemaker')
jobs = sm.list_processing_jobs()
pd.DataFrame(jobs['ProcessingJobSummaries'])[:1]
インスタンスの削除
Amazon SageMaker Processing で起動したインスタンスは自動で停止しますが、Amazon SageMaker Notebook 側で起動していたインスタンスは停止されないのでこちらは自分で停止します。立ちっぱなしで過重課金されないよう注意してください。
最後に
今回は、データ分析の前処理を想定して Amazon SageMaker Processing を使用しましたが、データ分析や機械学習以外にも python でデータを加工したい、といったユースケースで使えそうな機能だなと思いました。
ここまで読んでいただき、ありがとうございました!










